Running AI models in your terminal
If you haven’t been living under a rock for the past couple of years, you’re probably familiar with terms like ChatGPT or DeepSeek. These are popular artificial intelligence models which have recently taken the internet by storm. The more technical term for these AI models is large language models (LLMs), which belong to a specific family of machine learning models designed for natural language processing tasks such as text generation, summarization, and language translation.
The purpose of this post is not to delve into the theory behind LLMs as there are a myriad of articles out there that already cover this. Rather, we will focus on how to download and interact with some of the most popular LLMs directly from a PC terminal.
Downloading LLMs
It may come as a surprise to many, but there are numerous pre-trained open-source LLMs available for download and local setup. The most popular platform for this is Hugging Face, which hosts a vast collection of AI models, ranging from computer vision to natural language processing. Hugging Face equally provides APIs (e.g., in Python) which allow you to easily integrate these models into your applications.
Recently, I stumbled on Ollama, an even charmier framework that lets you download and run LLMs in your terminal with fewer than five lines of code–ideal for the lazy programmer that I am (and probably you too!). So, for this tutorial, we will focus on Ollama.
To download and install Ollama locally, follow the instructions on their website here. For Linux users, you can simply run the following command in your terminal:
1
curl -fsSL https://ollama.com/install.sh | sh
- Once Ollama is installed, you can download (i.e.,
pull) and run a model locally by using the commandollama run <model-name>. For example, to pull DeepSeek R1, enter the following command in your terminal:
1
ollama run deepseek-r1
This downloads the model to your local system and opens a prompt (as shown below), allowing you to interact with the model.
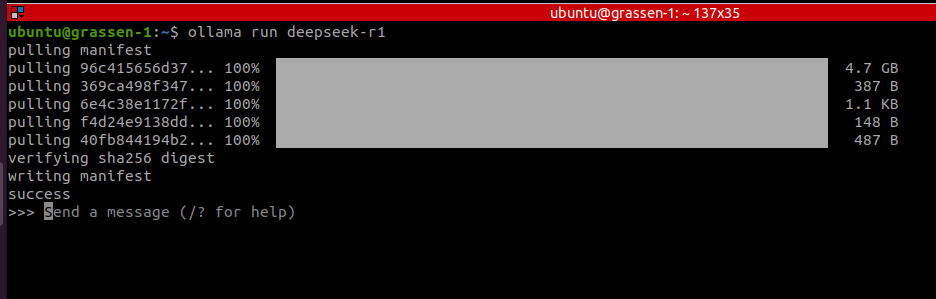
Enter a query like
what is an LLMand DeepSeek will generate a response for you!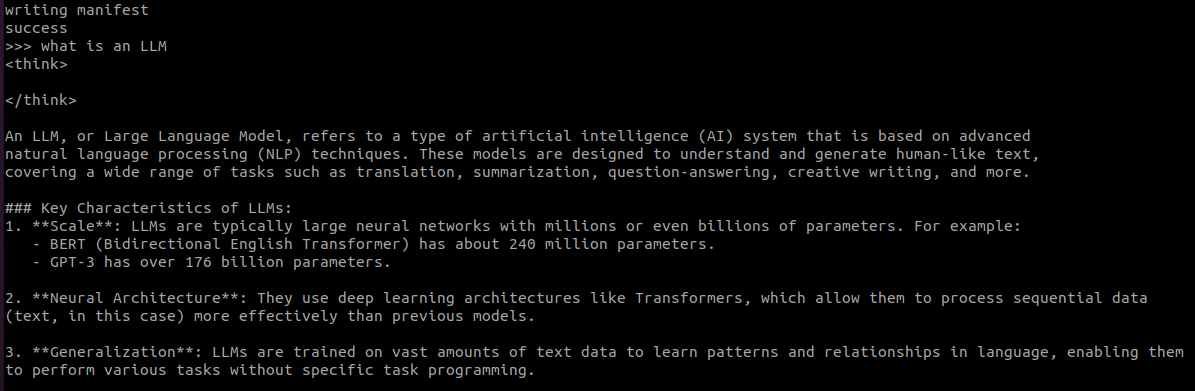
To summarize a large text file, do:
1
ollama run deepseek-r1 "Summarize the following text:" < document.txt
To use other models like Microsoft’s Phi4 or Meta’s LLama3, just head to Ollama and find the exact name to use with
ollama run.Personally, I find this approach way cooler than opening a web page every time I need to run queries. Even better, you can have multiple models available offline!
If you’re concerned about privacy, running LLMs locally can be a great option, as it allows you to avoid sending data to cloud services where you have no control over who accesses or handles it.
Model sizes
- If you visited the Ollama website, you have likely noticed that the models have various sizes.
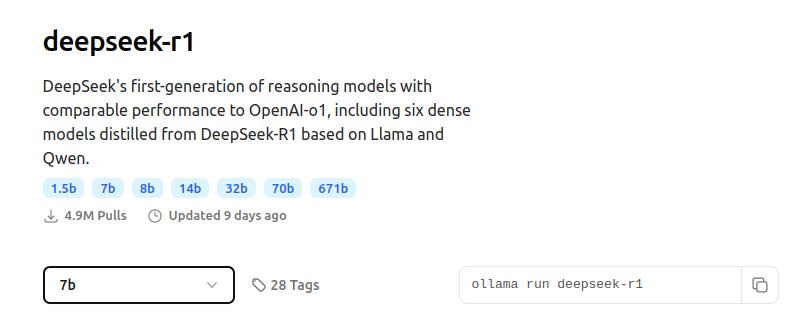
For example, DeepSeek R1 is available in multiple sizes: 1.5b, 7b, …, 671b. These numbers represent the number of parameters in the model. So 1.5b corresponds to the smallest model with 1.5 billion parameters, while 671b is the largest model with 671 billion parameters. A helpful way to understand these numbers is to think of them as analogous to “IQ scores”–the larger the number, the “smarter” the model, and vice versa.
- That said, running the largest DeepSeek R1 models (like
671b) requires additional hardware like GPUs to handle the computational load. For a regular CPU-only computer, it’s best to stick with the smaller models, ranging from1.5bto around32b.
Ollama commands
- Here are other practical commands for using Ollama.
1
2
3
4
5
6
ollama pull <model-name> # Downloads the model to your local system without running it
ollama list # Lists all downloaded models
ollama rm <model-name> # Removes/deletes the model locally
Ctrl + C # Stops text generation by the model
Ctrl + D # Closes the interactive prompt
/bye # Same as Ctrl + D: closes the interactive prompt
Using Ollama in a Python program
If you’re a programmer like myself, you might also be wondering how to integrate these models into a Python program. Thankfully, the Ollama framework provides tools to do just that.
To use Ollama in a Python program, first install the
ollamaPython package withpip install ollama. Once installed, you can use the models you’ve downloaed with Ollama in your Python program as follows.
1
2
3
4
5
6
7
8
import ollama
response = ollama.chat(model='deepseek-r1', messages=[
{
'role': 'user',
'content': 'Why is the sky blue?',
},
])
print(response['message']['content'])
To use a different model, simply change the value in
model=to the target model. For example, settingmodel='llama3'will use Meta’sLLaMA3model instead.
I’m sure you’ll agree that this is really a fun way to experiment with AI models!!. If you are not comfortable with the terminal or CLI, I suggest you go for a tool like LM Studio which allows you to download and interact with LLMs via a user-friendly GUI.
In the next tutorial, we will build a simple web search application that runs on a local model.